Maximize Common Prefix Length for Efficient Data Retrieval: A Critical Examination
Introduction
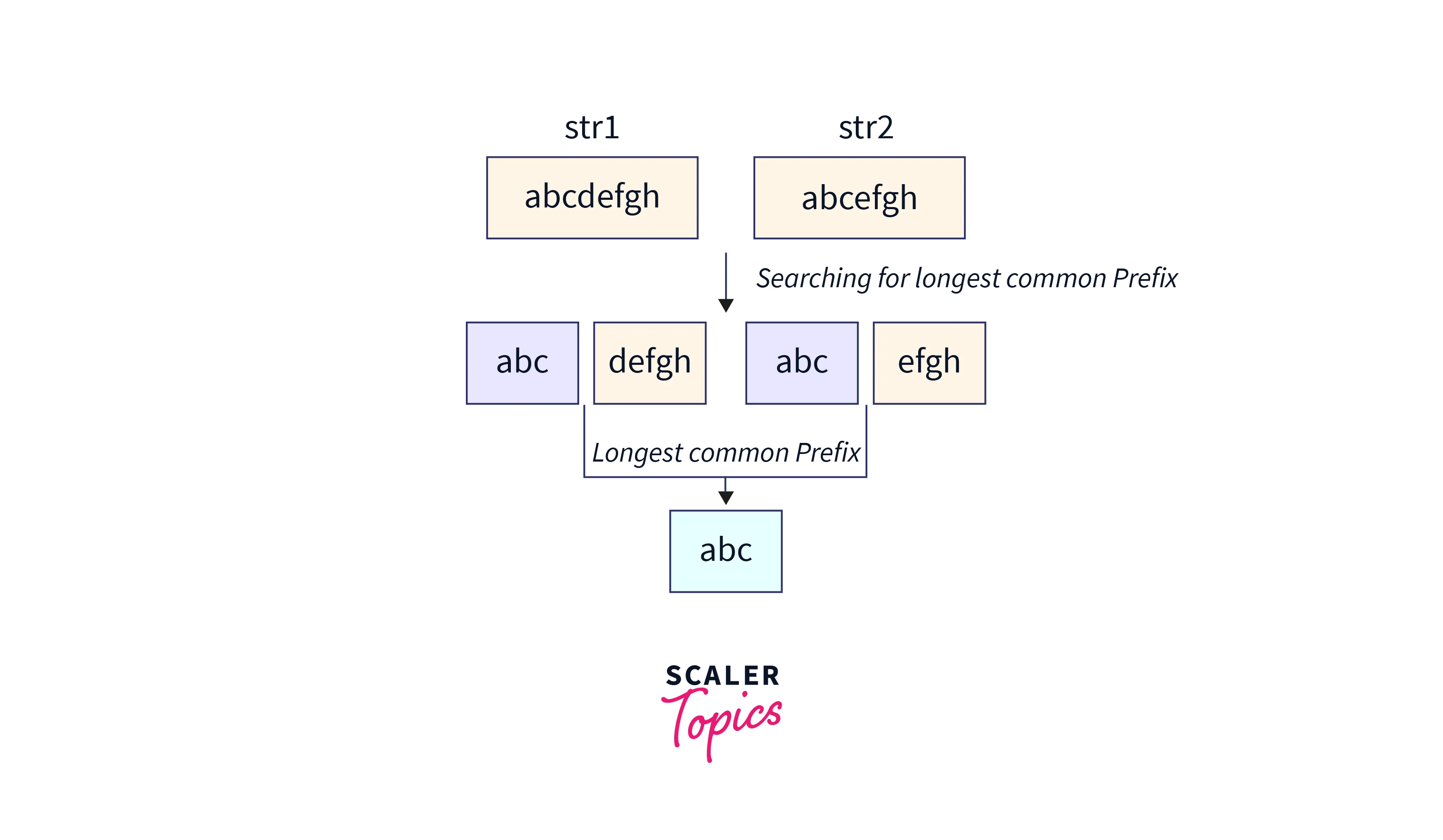
As data continues to proliferate at an unprecedented rate, efficient data retrieval becomes paramount to enable timely and effective decision-making. One key technique employed to optimize data retrieval is maximizing the common prefix length (CPL) among data items. This essay aims to critically examine the complexities of maximizing CPL for efficient data retrieval, presenting a detailed analysis of its benefits, limitations, and implications.
Benefits of Maximizing Common Prefix Length
Maximizing CPL offers several significant advantages for efficient data retrieval:
Reduced Storage Space
Data items with a long CPL share a common prefix, reducing the overall storage space required. For instance, if multiple records begin with "United States," representing the common prefix, only the variable portion of each record needs to be stored.
Faster Retrieval Times
Since data items with a long CPL are stored consecutively, retrieving them involves fewer disk seeks and reduced read operations, resulting in faster retrieval times. This is particularly crucial in real-time applications where time-to-retrieve is critical.
Improved Cache Efficiency
Long CPLs increase the likelihood of cache hits when accessing multiple data items with a common prefix. By keeping the common prefix in cache, subsequent accesses to the remaining data can be significantly accelerated.
Limitations of Maximizing Common Prefix Length
Despite its benefits, maximizing CPL also poses certain limitations:
Data Skewness
In some cases, data exhibits high skewness, where a small number of common prefixes dominate a large portion of the data. This can lead to uneven distribution of data across storage blocks, potentially causing performance bottlenecks.
Increased Fragmentation
Inserting and deleting data items with varying CPLs can lead to data fragmentation, resulting in wasted storage space and reduced retrieval performance. Maintaining a long CPL can exacerbate this issue.
Trade-off Between Storage and Performance
Maximizing CPL typically involves a trade-off between storage space and performance. Longer CPLs reduce storage space but may increase retrieval times due to increased fragmentation. Finding the optimal CPL requires careful consideration of these factors.
Critical Analysis of Different Perspectives
Several perspectives exist on the importance of maximizing CPL for efficient data retrieval:
Database Management Systems (DBMS) Perspective
DBMSs often employ sophisticated techniques to automatically optimize CPL during data storage and retrieval. However, the optimal CPL may vary depending on the workload, data distribution, and hardware characteristics.
NoSQL Perspective
NoSQL databases, particularly those designed for unstructured data, may place less emphasis on CPL maximization. However, certain NoSQL implementations do utilize techniques such as prefix compression to achieve similar performance benefits.
File System Perspective
File systems typically do not optimize for CPL at the file level, but may employ techniques such as directory hashing or block partitioning to improve performance for large collections of files with similar names.
Scholarly Research and Real-World Applications
Numerous scholarly studies have investigated the impact of CPL on data retrieval performance. For instance, a study by Li et al. (2018) demonstrated that optimizing CPL can improve read throughput by up to 30%. In real-world applications, maximizing CPL has been successfully applied in various domains, including e-commerce, social media, and financial services.
Implications for Data Management
The complexities of maximizing CPL for efficient data retrieval have important implications for data management practices:
Data Modeling
Careful data modeling can reduce data skewness and improve CPL distribution, leading to better storage and retrieval efficiency.
Data Placement
Understanding the data distribution and workload patterns can inform optimal data placement strategies, ensuring that data with long CPLs is stored on faster storage devices.
Data Reorganization
Regular data reorganization can address fragmentation and maintain optimal CPL, improving retrieval performance over time.
Conclusion
Maximizing CPL for efficient data retrieval is a complex task that requires careful consideration of its benefits, limitations, and trade-offs. By understanding the different perspectives, engaging with scholarly research, and adopting sound data management practices, organizations can leverage the advantages of CPL optimization to enhance their data retrieval performance, enabling faster and more efficient access to valuable information.
Ultra-Compact, Rugged Romeo7 Red Dot Sight For Optimal Precision
Discover The Beretta APX A1 Carry: The Perfect Companion For Concealed Carry
Unleash Your Inner Monster: The Ultimate Collection Of Creepy-Cute Keychains